
Einführung: Was ist gpt-oss-safeguard?
OpenAI hat kürzlich die Forschungs-Preview von gpt-oss-safeguard veröffentlicht: Es handelt sich dabei um zwei Open-Weight-Modelle (größere Variante „120B“ und kleinere Variante „20B“) unter Apache 2.0-Lizenz, die speziell für Sicherheits- und Klassifikationsaufgaben entwickelt wurden.
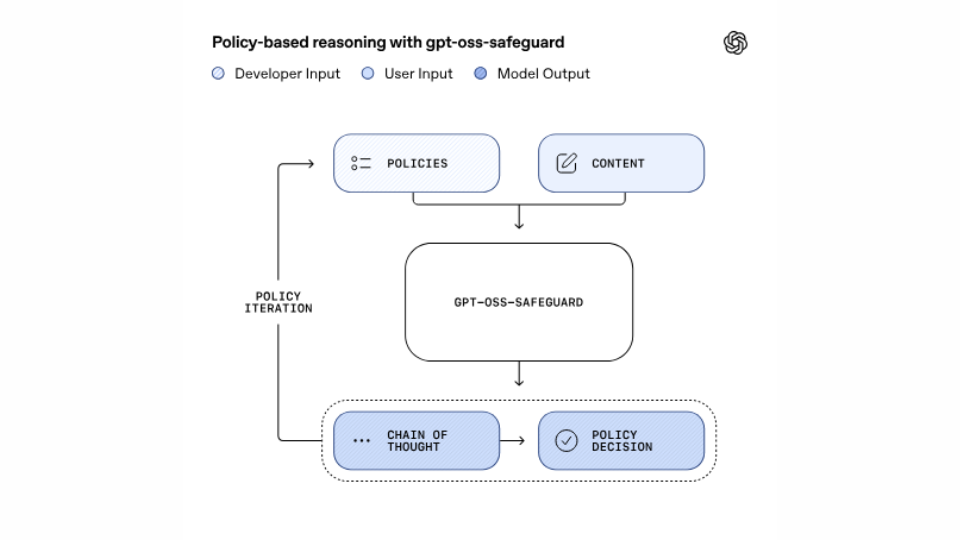
Im Kern liegt der Unterschied zu früheren Klassifikatoren darin, dass gpt-oss-safeguard Reasoning verwendet – also Ketten von Überlegungen („Chain-of-Thought“) –, um eine von Entwicklern definierte Policy direkt beim Inferenzzeitpunkt anzuwenden und zu erklären.
Einfach gesagt: Während klassische Sicherheitssysteme oft fest trainierte Klassifikatoren sind, erlaubt gpt-oss-safeguard Entwicklern, ihre eigenen Regeln („What counts as unsafe?“) reinzugeben und das Modell dann direkt anzuweisen, diese Regeln bei Chats, Antworten oder Nutzeranfragen anzuwenden.
Technische Eckdaten & Besonderheiten
Varianten: gpt-oss-safeguard-120B und gpt-oss-safeguard-20B.
Verfügbar als Open-Weight-Modelle unter Apache 2.0 Lizenz – das heißt: Jeder Entwickler kann die Modelle herunterladen, modifizieren und einsetzen.
Der Fokus liegt auf Klassifikation und Sicherheit – nicht darauf, Hauptanwender-Dialoge zu führen. OpenAI weist darauf hin, dass nicht empfohlen wird, gpt-oss-safeguard direkt für Endnutzer-Chats einzusetzen.
Ein wichtiger Aspekt: Das Modell liefert Erklärungen („Chain of Thought“), wie es zu einer Entscheidung gekommen ist – also eine höhere Transparenz gegenüber klassischen Black-Box-Klassifikatoren.
Warum ist das bedeutsam?
Für Entwickler, Unternehmen oder Plattformen, die Sicherheit, Moderation oder Nutzungsrichtlinien automatisieren wollen, bietet gpt-oss-safeguard wichtige Vorteile:
Flexibilität: Policies lassen sich austauschen oder modifizieren, ohne das Modell komplett neu zu trainieren.
Transparenz: Durch Erklärungen der Bewertung („War dieser Text gefährlich? Warum ja/nein?“) wird Nachvollziehbarkeit verbessert – ein Plus bei Compliance, Audits oder regulatorischen Anforderungen.
Offenheit: Open-Weight heißt, Entwickler können das Modell herunterladen und selbst hosten – etwa nützlich für Einsatz in Umgebungen mit sensiblen Daten oder lokalem Betrieb.
Sicherheits-Infrastruktur-Ausbau: Als Komponente in einer größeren Sicherheitspipeline kann das Modell dazu beitragen, Risiken zu erkennen – etwa bei Hate Speech, Selbst-Schädigung oder komplexeren Schadensfällen.
Insbesondere im Umfeld von ChatGPT und ChatGPT Deutsch ist die Einführung solcher Modelle bedeutsam: Wenn Dienste mit großen Sprachmodellen betrieben werden, steigt der Bedarf, Inhalte sicher, regelkonform und nachvollziehbar zu moderieren.
Anwendung im Kontext von ChatGPT & ChatGPT Deutsch
Für Nutzer oder Betreiber von ChatGPT (inkl. deutschsprachiger Anwendungen „ChatGPT Deutsch“) ergeben sich folgende Potenziale:
Betreiber von Chatbot-Plattformen können gpt-oss-safeguard einsetzen, um eingehende Nutzeranfragen oder generierte Antworten zu prüfen, bevor sie einem Endnutzer angezeigt werden. So lässt sich das Risiko unerwünschter Inhalte senken.
In deutschsprachigen Projekten können eigene Policies in deutscher Sprache integriert werden („Keine rechtsextremen Inhalte“, „Kein medizinischer Rat ohne Disclaimer“ etc.) und Modelle entsprechend agil angepasst werden.
Content-Creator, die ChatGPT Deutsch nutzen, profitieren indirekt: Je besser die Moderation und Sicherheit der Plattformen, desto höher die Qualität und Zuverlässigkeit der generativen Inhalte.
Für Unternehmen, die ChatGPT-Deployments betreiben (z. B. als interner Assistent oder Content-Tool), stellt gpt-oss-safeguard einen Baustein dar, um interne Compliance-Regeln abzubilden und Automatisierung sicherer zu gestalten.
Grenzen & offene Fragen
Trotz aller Vorteile sind auch zentrale Limitationen zu beachten:
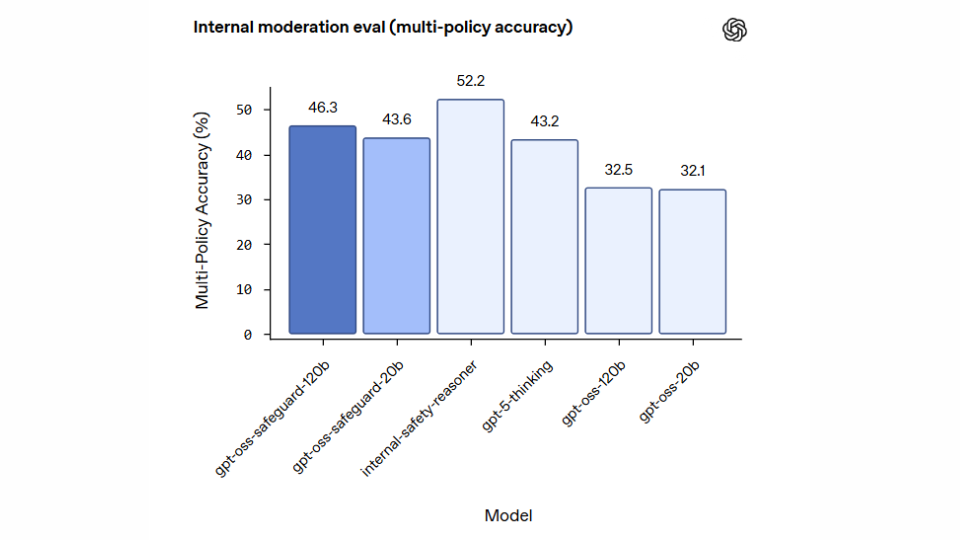
OpenAI selbst weist darauf hin, dass klassisch trainierte Klassifikatoren in bestimmten sehr anspruchsvollen Szenarien noch überlegen sein können – insbesondere bei extrem komplexen oder subtilen Risiken.
Reasoning-Modelle sind oft rechenintensiver oder langsamer als reine Klassifikatoren – das kann bei Echtzeit-Anwendungen oder hoher Last relevant sein.
Da Policies völlig flexibel sind, hängt die Effektivität stark von ihrer Qualität ab – also vom „Handbuch“, das ein Entwickler definiert. Schlechte Policies können zu inkonsistenten oder falschen Ergebnissen führen.
Obwohl offene Modelle spannend sind – das Risiko des Missbrauchs bleibt: Ein Modell, das für Klassifikation gedacht ist, könnte auch in andere Systeme integriert werden. OpenAI warnt vor einer Verwendung im Endnutzer-Dialog.
Ausblick & Bedeutung für die KI-Sicherheit
Mit gpt-oss-safeguard setzt OpenAI ein wichtiges Signal: Sicherheit und Moderation werden nicht nur als Add-on behandelt, sondern als integraler Teil von KI-Modellen selbst. Die Offenheit dieser Modelle fördert zudem die Forschung und Gemeinschaftsarbeit im Bereich „Trust & Safety“.
Für deutschsprachige Entwickler und Nutzer heißt das: Es besteht die Chance, eigene Sicherheits-Policies lokal anzuwenden – z. B. in Projekten mit ChatGPT Deutsch –, und somit Kontrolle zurückzugewinnen über generative Inhalte und deren Moderation.
Zukünftig könnte man sehen, dass solche Modelle nicht nur klassifizieren, sondern auch aktiv steuern – etwa indem sie automatisch alternative Formulierungen vorschlagen oder Inhalte präventiv anpassen. Die „Chain of Thought“-Erklärungen machen das System dabei auditierbar.
Fazit
gpt-oss-safeguard markiert einen wichtigen Meilenstein bei OpenAI: offene Sicherheits-Modelle, die developerspezifische Policies verstehen und anwenden können, mit Transparenz und Offenheit. Wer mit ChatGPT oder ChatGPT Deutsch arbeitet – sei es als Nutzer, Entwickler oder Betreiber – sollte diese Entwicklung im Blick behalten. Sie signalisiert, dass generative KI zunehmend in eine Phase eintritt, in der Sicherheit, Kontrolle und Verantwortung zentral sind – nicht nur Funktionalität und Kreativität.